WordLister |
|
Università degli Studi di Torino.
This tool lists the words (rightly the tokens) in a text as a concordancer (but it doesn't print the contexts) and computes the frequencies of each word.

An example of what you get from WordLister: a list of the tokens and their frequency in the text.
It's only a simple AWK script, and, of course, anyone in the computational linguist's community can do it just from scratch even better, but usually philologists (at least most of my friends) don't. So, here it is, mainly for them.
The text (in TXT format) must be already clean and tokenized according to the contingent needs. The script must be called in the usual manner from a textual consolle, and then you have to run a Sort:
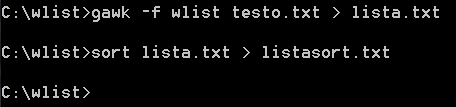
Of course, you must already have a GAWK in the current directory. You can download it directly from the Free Software Foundations web site. For Microsoft systems it is possible to download the last version of GAWK from the Sourceforge web site.
This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. You should have received a copy of the GNU General Public License along with this program; if not, write to the Free Software Foundation, Inc., 59 Temple Place - Suite 330, Boston, MA 02111-1307, USA.
You can download WordLister here