Introduzione alla linguistica generale.
Materiali integrativi al corso di Didattica delle lingue moderne.
di Manuel Barbera (b.manuel@inrete.it).
2. Le lingue.
2.0 Introduzione: lingue, classificazioni e genealogia.
2.0.0 Introduzione.
Nella sezione precedente avevamo cercato di spiegarci cosa sia
il linguaggio, delineandone le caratteristiche affatto generali ma soffermandoci soprattutto
su quelle del linguaggio umano in particolare. Qui ci occuperemo invece delle lingue
storiche, parlate dagli uomini in dati punti del tempo e dello spazio.
Nei capitoli seguenti, piů precisamente, introdotte alcune necessarie premesse
sulla classificazione linguistica e sulla linguistica storica, presenteremo una panoramica
dell'Eurasia linguistica, in base a due punti di vista: (a) corredare i problemi teorici della
classificazione genealogica di esempi concreti che servano al contempo ad illuminare
le aree culturali che studiamo; (b) fornire una serie di esempi di fenomeni linguistici
che appaiano in modo esemplare in lingue o famiglie raggiunte dalla nostra rassegna,
in modo da ampliare l'esemplificazione del manuale di Graffi - Scalise, basata
prevalentemente sull'italiano e sull'inglese; (c) dato che tutta la manualistica (con, probabilmente,
la sola meritoria eccezione di Lyle Campbell,
Hystorical Linguistics. An Introduction, Edimburgh, Edimburgh University Press, 1998, un manuale molto ricco che caldamente consiglio
a chi scoprisse di essere interessato alla linguistica storica) č
prevalentemente focalizzata sull'indoeuropeo, e che l'interesse della maggior parte
dei miei studenti č piuttosto spostato sull'Asia, trascureremo molto l'indoeuropeo per mettere
in maggior in rilievo, invece, le altre famiglie linguistiche dell'Eurasia.
Certo, č spiacevole limitarsi alla sola Eurasia, come se le Americhe, l'Oceania e l'Africa
non serbassero anche loro scrigni preziosi di diversitŕ linguistica, ma in un corso
di 60 ore bisogna per forza fare rinunce dolorose ...
2.0.1 Lingue vs. linguaggio: la lingua come "specie".
Avevamo ripetutamente insistito nella sezione precedente, tanto
parlando della fondazione del linguaggio come istituto "sociale" (da Saussure a
Wittgenstein) quanto della sua possibile origine (biologica evoluzionistica e
biosemiotica), sulla radicale differenza tra le lingue storiche sviluppate, in
diverse zone del tempo e dello spazio, dall'umanitŕ ed il linguaggio come istituto
(Saussure ecc.) o facoltŕ generale (Chomsky). La distinzione tra lingua (anzi,
meglio, "lingue") e linguaggio č in effetti davvero fondamentale.
Una analogia potrebbe essere in biologia la distinzione tra specie (unitŕ di
"popolazione" vivente: cfr. "lingue") e vita (condizione comune a tutte le
"popolazioni": cfr. "linguaggio"). Alla stessa maniera che la specie č l'unitŕ
tassonomica base della scienza naturale, la "lingua" puň essere considerata
l'unitŕ base della linguistica naturale.
Anche il problema dell'origine del linguaggio deve essere rigorosamente distinto
da quello delle lingue storiche umane. Č infatti spesso capitato che si sostenesse
la tesi della monogenesi delle lingue chiamandola erronemaente (e talvolta anche
fraudolentemente) "monogenesi del linguaggio": tale tesi sostiene che tutte le
lingue odierne sarebbero evolute da una unica lingua progenitrice, allo stesso modo che
tutti gli uomini hanno una unica origine genetica, (e non che il linguaggio sia una
struttura fondante della vita stessa, come abbiamo visto essere probabilmente vero).
Giŕ nell'Ottocento i linguisti piů avveduti rifiutavano tali questioni (che
chiamavano "glottogoniche"), in quanto scientificamente intrattabili. L'idea,
perň, non č mai davvero tramontata, e nella seconda metŕ del Novecento č rinata
piů forte di prima, col presunto appoggio della genetica (si tratta, in realtŕ,
di una illusione dovuta, tra l'altro, all'equivoco tra lingue e linguaggio). Non č
tra l'altro mancato l'appoggio (abbastanza inspiegabile) di linguisti illustri, come
Morris Swadesh
(1909-1967, noto specialista di lingue amerindie) e Joseph Greenberg (1916-2001,
il fondatore della tipologia moderna), né la diffusa divulgazione ad opera di mistificatori
dai pochi scrupoli come Merrit Ruhlen.
In realtŕ, basandoci sugli unici "dati" che abbiamo - ossia le lingue
esistenti od esistite che conosciamo - e sull'unica metodologia che ci garantisca
risultati scientificamente controllabili - il "metodo storico-comparativo", su cui
torneremo in seguito - arriviamo a dimostrare l'esistenza di circa 250
famiglie linguistiche (di cui 37 nella sola Eurasia), con un certo numero di lingue
che rimangono isolate (non connesse con alcuna unitŕ genealogica verificabile);
per alcune di queste famiglie esistono ipotesi di connessioni genealogiche in altre
unitŕ piů vaste, ed alcune di queste ipotesi č anche probabile che vengano di fatto
dimostrate in futuro: ma resta il fatto che non si riesce empiricamente, a posteriori,
ad arrivare neanche lontamente vicino alla origine unica, ed ogni supposta "dimostrazione"
che ne č stata divulgata č viziata da un erroneo utilizzo del metodo comparativo e/o
da un troppo disinvolto uso dei dati linguistici (sono nate non solo parole inesistenti
ma anche lingue inesistenti ...).
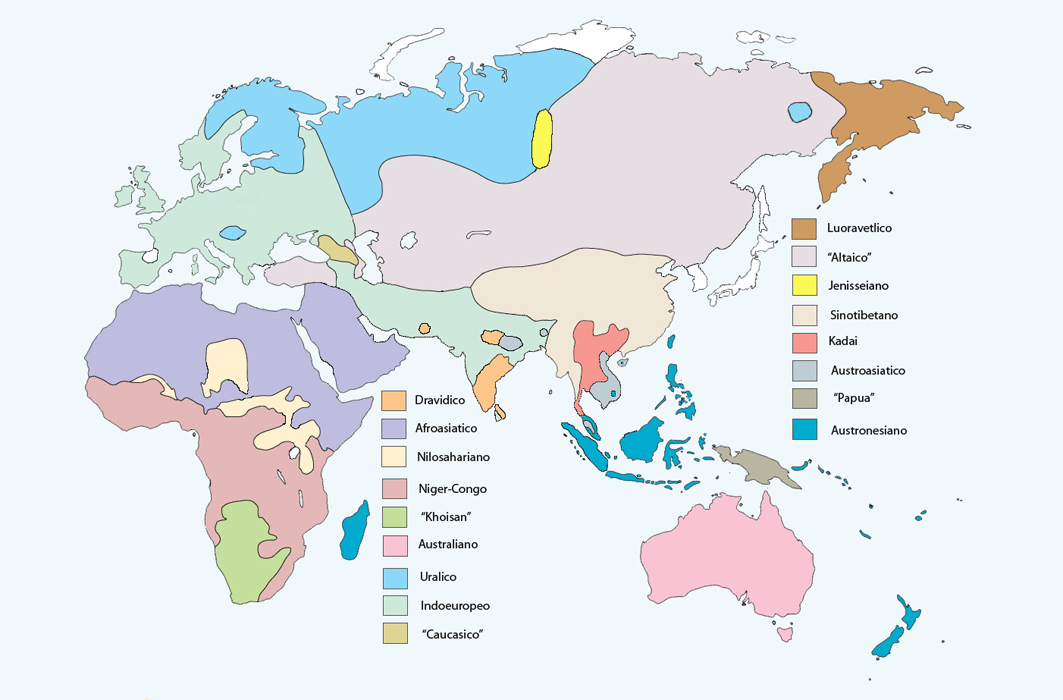
[tav. 1]
La geografia linguistica dell'Europa, dell'Asia, dell'Africa e di parte dell'Oceania.
La cartina rappresenta solo le grandi linee della situazione, in modo "arcaico" (cioč
grossomodo all'inizio dell'era moderna, ma senza tenere conto dell'invasivitŕ delle
lingue indoeurope e dei vari fenomeni coloniali e delle piů o meno recenti estinzioni)
ed a spanna. I confini geografici, infatti, sono molto approssimativi; le lingue isolate
non sono in genere rappresentate (e tali a vario titolo si sono considerati basco,
koreano, giapponese, ainu e nivkh) e le loro rispettive aree sono state lasciate bianche;
famiglie molto disperse come le miao-yao non sono state rappresentate del tutto; molte
realtŕ o discusse (come l'altaico) o piů o meno discutibili (come da un lato il khoisan
e dall'altro l'australiano), o discutibilissime (come le lingue caucasiche,
in realtŕ tre famiglie distinte), quando non puramente geografiche e di comodo (come
l'etichetta "papua", che ricopre incontestabilmente una trentina tra famiglie diverse
e lingue isolate), sono state accomunate sotto un'unico colore; la distinzione tra
lingue austronesiane e non (cioč "lingue papua") in Oceania č stata sostanzialmente
ignorata; le lingue lapponi (uraliche) in Scandinavia sono rappresentate in modo risibile,
come anche le lingue khoisan in Sudafrica; ecc.
Spero che la tavola pur con tutte queste manchevolezze renda almeno l'idea.
La base, fortemente rielaborata, č stata fornita dalla tavola a pag. 598 di Jared Diamond
- Peter Bellwood, Farmers and Their Languages: The First Expansions, in «Science»
CCC (2003) pp. 597-603.
Resta il presunto argomento che la monogenesi sarebbe
la tesi piů "economica" per spiegare l'emergenza delle lingue umane: il che č naturalmente
vero per il linguaggio, come per le specie biologiche, ma per le lingue č
assolutamente falso. Per le specie (almeno per quelle eucariote, dotate di riproduzione
sessuata, diploide) esiste infatti la barriera riproduttiva, ossia il fatto che
la riproduzione non puň avvenire tramite accoppiamento di due membri di specie
diverse; i contorni possono essere piů (si pensi al fenomeno dell'ibridazione) o
meno sfumati (un asino ed un cavallo, ad esempio "possono" accoppiarsi, ma la
loro prole, il mulo, č sterile), ma il fatto č ben assodato, ed anzi č stato alla
base della definizione stessa di specie prima che lo studio dei procarioti (asessuati)
imponesse che venisse affiancato da altre caratteristiche. Per le lingue, invece,
a quanto sappiamo č vero proprio il contrario: lingue diverse si possono egregiamente
fondere in nuove lingue (č il cosiddetto fenomeno della creolizzazione: conosciamo
infatti molte lingue creole delle quali sappiamo anche abbastanza bene come "si sono create")
e ogni lingua puň assumere una parte del proprio patrimonio da altre lingue (basti pensare
ai prestiti nel lessico ...). Č, in pratica, come se per un organismo vivente il
patrimonio genico non venisse di norma trasmesso linearmente ma riassemblato diffusionalmente
con pezzi di genoma di diversa provenienza .... Dunque, la monogenesi per le lingue
NON č la teoria piů economica (mentre lo č per le specie).
E poi: dobbiamo pure, in qualche modo rendere conto del grado di
diversitŕ linguistica presente nel mondo.
Un calcolo approssimativo (l'approssimazione č dovuta non solo alla nostra
conoscenza ancora imperfetta di alcune aree "selvagge" come la Nuova Guinea, ma anche
alla instabiltŕ stessa del concetto di "lingua", cfr. il paragrafo sg.) porrebbe
il numero delle lingue esistenti intorno alle 6.000. Questo dato quantitativo, in
sé molto alto, č probabilmente l'unico fatto oggettivo inconfutabile riguardo alla
diversitŕ linguistica del mondo. Qualitativamente, infatti, la valutazione della
"glottodiversitŕ" (se cosě vogliamo chiamare il fenomeno in questione, in analogia
con la "biodiversitŕ" che studiano i naturalisti) č inevitabilmente legata a reazioni
soggettive e ad aspettative diverse in base alle diverse teorie linguistiche
dell'osservatore: un linguista di formazione storica ed empirica sarŕ colpito
dalla straordinaria diversitŕ delle lingue, mentre uno studioso
di formazione piů razionalista e generativista sarŕ piuttosto colpito dalle somiglianze,
specie a livello di struttura profonda. Entrambe le reazioni sono probabilmente giustificate,
e rispondono a diversi progetti di studio. Provate a guardare le due seguenti frasi,
l'una traduzione dell'altra, in eskimo groenlandese (Kalaallit oqaasii, "Western
Greenlandic", la lingua ufficiale della Groenlandia) ed in inglese:
| Kal. naalaqqisaaqquaa |
| naala- | qqisaa- | qqu- | aa |
| 'ascoltare' | 'attentamente' | 'dire a' | 3/SOG.3/OGG.IND |
| Eng. he told him to listen carefully |
| he | told | him | to listen | carefully |
| 3.SOG | 'dire'-PT | 3.OGG | INF-'ascoltare' | 'attentamente' |
[tav. 2]
Due frasi dallo stesso significato in eskimo groenlandese ed in inglese. Nell'analisi
linguistica i numeri (3) stanno per la persona verbale o pronominale, IND per
"indicativo", INF per "infinito", PT per "passato", SOG per "soggetto" ed OGG per
"oggetto". L'esempio č adattato da Michael Fortescue, Western Greenlandic, London
- Sydney - Dover, Croom Helm, 1984, p. 43.
La diversitŕ tra le due lingue č innegabile, ma lo č anche il fatto
che entrambe rispettano la structure dependency
almeno per quanto riguarda il principio di proiezione e la teoria x-barra (se provate
a costruire, seguendo le indicazioni mie e del manuale di Graffi-Scalise, un albero
sintattico della frase in eskimo, vedrete che č un esercizio forse non facile, ma
comunque possibile), come prevede la teoria di Chomsky.
Seguire una strada piuttosto che un'altra č piů che altro funzione dei vostri interessi
e di quello che volete studiare in una lingua: la singolaritŕ e la specificitŕ delle
sue strutture, dal punto di vista diacronico della loro formazione o da quello
sincronico del loro attuale funzionamento, o piuttosto i principi generali, la struttura
profonda - come si usa dire nella tradizione generativa - che la determinano.
2.0.2 Definizione di lingua e criteri per determinare una lingua.
Ma cosa sarŕ poi, in fin dei conti, una lingua? Se non ci fosse giŕ stato intuitivamente
presente, ormai dovremmo averlo abbastanza chiaro: una specifica forma di linguaggio
usata da una determinata popolazione in un certo punto dello spazio e del tempo.
Anche se il concetto č ben definito, questo non significa che, concretamente, ci serva
a molto per identificare una lingua. Anzi, č purtroppo vero che identificare una
lingua, ossia distinguere univocamente una varietŕ linguistica da un'altra varietŕ
a lei prossima nello spazio geografico, sociale, culturale, temporale, ecc. (tanto
sullo stesso piano, lingua vs. lingua, quanto su piani subordinati, lingua vs.
dialetto, considerato quest'ultimo come sottovarietŕ della lingua), č un'operazione
a volte estremamente difficile, e spesso non c'č alcun consenso né sui criteri da
adottare né sui risultati da cercare.
Esempi di questa incertezza sono sotto gli occhi di tutti. Io, ad esempio, mi riferisco
alla mia madrelingua piemontese come "lingua", ma un politico vi si riferirebbe (con
intenti probabilmente diminutivi) come ad un "dialetto" - ed una analoga esperienza
potrebbe essere capitata anche ad alcuni di voi. Nella legislazione italiana, per
fare un altro esempio, il friulano ed il ladino sono considerati "lingue" minoritarie,
e sono pertanto in qualche modo salvaguardate, ma il piemontese od il veneto no,
nonostante nessun linguista (per tacere di nessun vero piemontese o veneto) nutrirebbe
dubbi sul loro "esser lingue". Un altro esempio, che muove in senso contrario,
puň essere dato dal croato e dal serbo, di cui le nazioni che ne contengono la
maggioranza dei parlanti si sono sforzate di trattarle come "lingue" diverse, cercando di nasconderne
le somiglianze con l'uso di scritture diverse (l'una latina, e l'altra cirillica) e
col favorire scelte lessicali divergenti, ma che vengono di solito considerate dai
linguisti come due varietŕ di una stessa lingua, il "serbocroato". A volte la
differenziazione od il livellamento non sono neppure introdotti di forza da una
volontŕ politica nazionalista, ma sono il naturale risultato di una diversitŕ culturale
tra comunitŕ che pure fanno uso di uno strumento linguistico sostanzialmente simile:
č questo ad esempio, in India, il caso di hindi ed urdu, che sono divise da diversa
scrittura (nagari vs. arabica), religione (induista vs. islamica), cultura e letteratura,
pur essendo due forme della medesima lingua, ed entrambe reciprocamente non riducibili
a dialetto l'una dell'altra.
Che criteri sono, insomma, di norma usati per l'identificazione di una "lingua"? Ve ne sono
molteplici, schematicamente riconducibili a due gruppi generali: criteri extralinguistici
e criteri linguistici.
Iniziamo da quelli extralinguistici che pure, facendo noi linguisti "by trade, ci
interessano intrinsecamente meno.
Il piů tipico nel nostro Occidente, figlio nel bene e nel male dal nazionalismo
romantico dell'Ottocento, č il criterio nazionale: una lingua č tale se č
la varietŕ standard di uno stato nazionale sovrano. Cosě, il sardo, la piů isolata
ed originale tra le lingue romanze, sarebbe un mero "dialetto" dell'italiano, come anche
il mio povero piemontese; anche il basco, che pure č la lingua piů aberrante e storicamente
inspiegata di tutta Europa, diventerebbe un "dialetto" dello spagnolo (o del francese?
che anche questa č un'altra contraddizione di questo approccio); il lussemburghese, invece,
che ogni germanista sa essere un dialetto medio-tedesco del gruppo francone mosellano,
č invece la "lingua" ufficiale dello stato del Granducato del Lussemburgo. Il criterio,
evidentemente, non č utile dal punto di vista linguistico, ed č anche piuttosto funesto
nelle sue conseguenze politiche e culturali.
Meno esiziali, e di fatto talvolta utili per determinati scopi, possono essere i
criteri sociolinguistici, culturali e di prestigio culturale o letterario.
Da questi punti di vista, ad es., praticamente tutte le varietŕ linguistiche presenti
in Italia si trovano sotto l'ombrello dell'italiano, rispetto al quale si pongono
sostanzialmente in un rapporto di dipendenza lingua-dialetto, cosa che (purtroppo)
č un dato di fatto, anche se contraddice la natura strettamente linguistica
e storica di quelle varietŕ, e del quale bisogna per forza tenere conto.
I criteri linguistici sono comunque, naturalmente, i piů pertinenti per
identificare una lingua in quanto tale; idealmente, anzi, dovrebbero essere i soli
a contare realmente, sennonché le lingue sono pur sempre costruzioni sociali ...
Il criterio piů "ingenuo" che ci si puň affacciare naturalmente alla mente č la
quantitŕ di coincidenza, ossia quanto delle regole e del lessico č simile od
uguale in due lingue. Nei casi estremi, ed un poco a spanna, le cose sono abbastanza evidenti:
nelle due frasi in eskimo ed inglese della tavola precedente non troviamo nulla di simile,
mentre tra i l'ŕj mŕl ao cňl e i l'ŕj mŕl al cňl, 'ho mal di collo' rispettivamente
nella parlata della bassa Valsusa ed in quella di Torino, le somiglianze sono molto piů
delle differenze (nel campione scelto la sola diversitŕ č nell'espressione dell'articolo determinativo,
[u] vs. [l]), sicché nel primo caso avremo due lingue diverse, mentre nel secondo
due dialetti della stessa lingua, o, piů accuratamente, due forme dello stesso "diasistema", nel
senso di 'sommatoria, matrice componenziale, di una serie di sistemi tra loro convergenti
in alcuni parametri e divergenti in altri' con cui č stato introdotto dal sociolinguista
Uriel Weinreich (in Is a Structural Dialectology Possible?, in "Word" X (1954) 388-400,
poi raccolto in italiano in Lingue in contatto, con saggi di Giuseppe Francescato,
Corrado Grassi e Luigi Heilmann, Torino, Bollati Boringhieri, 1974, traduzione
arricchita di Languages in Conctat, New York, 1953). Significativo, comunque,
č che il test in questione da solo non sia in grado di definire una percentuale assoluta
di divergenze che segni il confine tra lingue diverse: il metodo del diasistema č
descrittivamente efficace, ma discriminativamente inefficiente;
č proprio, in effetti, quando le cose non sono cosě nette, ossia proprio quando piů ci troviamo in
dubbio, che il sistema perde efficacia, e non consente di trarre decisioni definite.
Il secondo criterio cui potremmo fare ricorso č quello dell'intercomprensibilitŕ:
se tra parlanti di due varietŕ linguistiche non c'č comprensione reciproca (sia
pure imperfetta), allora ci troveremmo di fronte a due lingue distinte. Il criterio č a tutta
prima molto attraente, perché permette riscontri oggettivi ed č radicato su una
prerogativa essenziale della lingua, l'uso. Purtroppo anche in questo caso non č
tutto oro quel che luce ... Tutto il discorso presuppone che l'intercomprensione sia
simmetrica (se io capisco te, tu capisci me): purtroppo la comprensione,
come l'amore, non č detto che debba essere sempre ricambiata, ossia, piů formalmente,
non gode dalla proprietŕ reciproca. Forse un esmpio concreto ci aiuterŕ a comprendere
meglio la questione.
Una area in cui, nel corso del Novecento,
l'attivitŕ dei linguisti č stata particolarmente attiva nel definire le "lingue"
con cui dovevano confrontarsi (anche praticamente, per preparare programmi di istruzione
primaria in lingua) č il Messico, che č una delle zone a piů grande varietŕ linguistica
del mondo: nello stato di Oaxaca, in particolare, su una superfice di poco piů ampia
del Portogallo sono tuttora parlate circa cento lingue diverse, tra cui le piů numerose
sono le lingue zapoteche e le mixteche (entrambe appartenenti ad una delle famiglie
linguistiche piů vaste e meglio studiate dell'America, l' "otomangueo"). Per definirne
il numero (oggi stimato intorno risp. alle 38 ed alle 29: cfr. Jorge A. Suárez, The
Mesoamerican Indian Languages, Cambridge - London - New York - New Rochelle - Melbourne
- Sydney, Cambridge University Press, 1983, p. 18) si era pensato di fare ricorso in
larga scala ai test di intercomprensibilitŕ, con risultati affatto analoghi a quelli
che riporto qui sotto per un campione tre cittŕ zapoteche:

[tav. 3]
Percentuali di intercomprensibilitŕ in tre cittŕ zapoteche. La percentuale critica al
di sotto della quale non c'č piů comprensione accettabile si trova intorno all'80%,
o poco sotto (comunque non oltre il 70%): anche questo fattore si č rivelato, infatti,
in parte specifico lingua per lingua. Ma la conclusione piů interessante č che parlanti
di Yatzeche possono capire la variante di Ocotlán, e parlanti di Tilquiapan possono
capire la varietŕ di Yatzeche, ma i parlanti di Tilquiapan e di Ocotlán non si capiscono
tra di loro; c'č comprensione reciproca tra Yatzeche e Tilqiapan, ma mentre i parlanti
di Yatzeche capiscono quelli di Ocotlán non accade il contrario. Riprodotto da Jorge A.
Suárez, The Mesoamerican Indian Languages, Cambridge - London - New York - New
Rochelle - Melbourne - Sydney, Cambridge University Press, 1983, p. 15; basato su S.
Egland e D. Bartholomew, La inteligibilidad interdialectal en México: resultados
de algunos sondeos, México, Institudo Lingüístico de Verano, p. 79.
La situazione puň essere resa anche piů evidente con uno schema lineare
in cui, rispetto ad un centro, ogni singola linea ("isoglossa") rappresenta la percentuale
di comprensione, al cui interno piů punti possono essere raggruppati; una linea che racchiude
un punto od un gruppo di punti significa anche che alla percentuale indicata non ci possono
essere ulteriori raggruppamenti. L'esempio seguente rappresenta otto cittŕ dell'area
mixteca settentrionale:
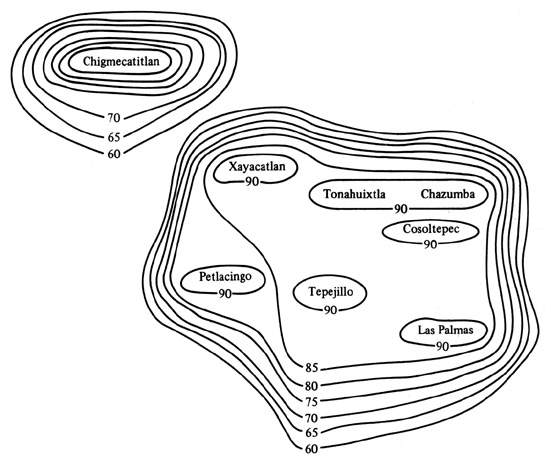
[tav. 4]
Percentuali di intercomprensibilitŕ tra le principali cittŕ zapoteche settentrionali,
rappresentate con isoglosse centrate su Chazumba. Per le lingue mixteche la percentuale
critica al di sotto della quale non c'č piů comprensione accettabile č stata fissata al
70% (per le lingue zapoteche č invece intorno all'80%: il fattore č, infatti, lingua-specifico).
Al 90% solo due punti possono essere raggruppati (Chazumba e Tonahuixtla), al 85% si
aggiungono altri quattro punti (Xayacatlan, Tepejillo, Cosoltepec e Las Palmas) ed
all'80% un ultimo ancora (Petlacingo). Dopo questa soglia, anche scendendo al 60%
nessun altro punto puň essere raggruppato: il punto piů prossimo, Chigmecatitlan, puň
essere aggiunto solo al 38%. In base a quello che abbiamo detto potremmo concludere
che in questa area ci troviamo di fronte a due lingue mixteche. Riprodotto da Jorge A.
Suárez, The Mesoamerican Indian Languages, Cambridge - London - New York - New
Rochelle - Melbourne - Sydney, Cambridge University Press, 1983, p. 17; basato su S.
Egland e D. Bartholomew, La inteligibilidad interdialectal en México: resultados
de algunos sondeos, México, Institudo Lingüístico de Verano, p. 29.
Per tirare le somme di quanto abbiamo detto, possiamo dunque
concludere che determinare esattamente una lingua č una operazione spesso delicata,
per la quale possono rendersi necessari anche piů criteri contemporaneamente, tra
i quali la preminenza va senz'altro data a quelli linguistici, senza tuttavia negarsi
il ricorso anche a criteri culturali e sociolinguistici. In pratica: bisogna decidere
caso per caso.
2.0.3 Classificazione e tassonomia.
Confrontarsi con la diversitŕ delle lingue del mondo e poterle
studiare in quanto tali significa anche attrezzarsi per "classificarle", non fosse
che per avere un sistema generale, condiviso da tutti gli studiosi, cui fare riferimento.
Tale necessitŕ non č poi molto diversa dalle istanze che mossero
Carolus Linnaeus,
il grande naturalista svedese (poi Carl von Linne, 1707-1778) nel 1735 a proporre
il suo Systema Naturae, che ha giocato un ruolo fondamentale nello sviluppo
delle scienze naturali, e la cui struttura (anche se, ovviamente, non la sua lettera)
č tutt'ora seguita nella "sistematica" biologica. In effetti, molte delle discussioni
sul concetto di "classificazione" che sono scorse copiose in tutta la storia delle
scienze naturali dal Settecento ad oggi sono illuminanti anche per il compito del
linguista. (Un affresco storico di quelle discussioni assolutamente stimolante č quello
che ne dŕ Enst Mayr nel suo The Growth of Biological Thought. Diversity, Evolution,
and Inheritance, Cambridge (Mass.) - London (UK), The Belknap Press of Harvard
University Press, 1982, tradotto come Storia del pensiero biologico. Diversitŕ,
evoluzione, ereditŕ, edizione italiana a cura di Pietro Corsi, Torino, Bollati
Boringhieri, 1990; cfr. in particolare le pp. 83-243 dell'ed. it. dedicate a La
diversitŕ della vita ed alla Macrotassonomia, la scienza della classificazione).
In particolare due ordini di considerazioni sono particolarmente importanti anche per la
classificazione delle lingue: quello relativo alla struttura (tassonomia) e quello
relativo ai criteri (arbitrarietŕ). In effetti, č la struttura del sistema linneiano,
inteso come una griglia di taxa (plurale del greco taxon 'posto'), ossia
una "tassonomia", ad essere ancora attuale (soprattutto la struttura binomiale dei nomi,
genere + specie, come Homo sapiens, la cui introduzione risale appunto a Linneo),
e non i principi con cui le specie (il taxon base) venivano definite e collocate
nella tassonomia (Linneo operava un secolo prima di Darwin, ed aveva, necessariamente,
un concetto non evoluzionistico, ed anzi essenzialistico, della specie).
Riproduco qui sotto, nella sua forma piů dettagliata, la tassonomia oggi in uso nella
sistematica biologica:
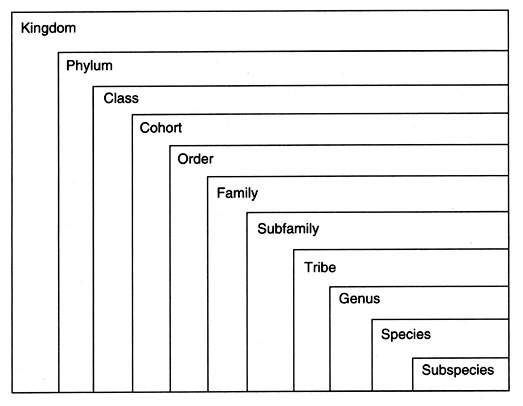
[tav. 5].
Nomi e gerarchia dei taxa nella tassonomia biologica moderna. La nomenclatura
nella tavola č in inglese; č ancora, comunque, spesso usato ancora il latino, che userň
invece in questa didascalia. Solo quattro taxa, ossia regnum, classis,
genus e species, risalgono al Systema originario di Linneo,
phylum invece č stato introdotto da Georges Cuvier
(1769-1832) nel 1799; quasi tutti i taxa possono contenere dei subtaxa quando necessario (quelli stampati sono i piů standard, ma sono frequenti
anche subphylum e subordo); cohors e tribus non sono usati in tutte le
tassonomie.
Riprodotto da Ernst Mayr, What Evolution Is, New York, Basic Books, 2001.
In linguistica non c'č ancora un consenso cosě consolidato sui taxa da
usare, cosa, se ci pensate bene, anche comprensibile date le difficoltŕ che abbiamo visto
nella determinazione del nostro taxon di base, la lingua (~ species), e del
suo immediato inferiore, il dialetto (~subspecies). Una esempio di classificazione
linguistica tassonomica (filogenetica ma anche sincronico-sociolinguistica e geografica:
č significativo, infatti che non si possa, in questo come in altri casi, fare una
classificazione "puramente" evolutiva) č quello che ho proposto per le lingue baltofinniche,
e che trovate nel capitolo dedicato alle lingue uraliche (cfr. la tassonomia BF).
Utile, in particolare, sarŕ un confronto tra i taxa della biologia e quelli
che ho impiegato per le lingue baltofinniche, che trovate compendiati in una apposita
tavola cui rimando.
Se l'articolazione e la consensualitŕ della griglia di classificazione,
compendiata nel concetto di tassonomia, č la prima lezione che abbiamo imparato
dalla sistematica biologica, l'altro punto fondamentale č quello della arbitrarietŕ
ed appropriatezza dei principi in base ai quali viene fatta una classificazione.
Giŕ intuitivamente č evidente che quando si fa una classificazione si hanno dei precisi
scopi pratici: se metto in ordine le minute ferramenta posso voler separare, ad esempio,
viti e chiodi lunghi da quelli corti perché ho due scatole di dimesioni diverse in cui
metterli, od invece voler separare viti da legno da bulloni da ferro perché ho zone diverse
del laboratorio per lavorare il legno ed il metallo. In entrambi i casi faccio una classificazione
decidendo di mio arbitrio (in base ai mie scopi) il criterio in base ai quali assegno
gli oggetti da classificare a taxa diversi.
Significativamente, come abbiamo rilevato, gli scopi (identificare e descrivere tutti
i vegetali e gli animali) ed i criteri (basilarmente il tipo di riproduzione) della
sistematica di Linneo sono diversi da quelli della biologia moderna, post-darwiniana, per
la quale lo scopo č piuttosto identificare la corretta filogenesi delle specie, e gli strumenti
impiegativi sono sempre piů le sequenziazioni geniche, anche se le caratteristiche morfologiche
(come quelle legate alla riproduzione, care a Linneo) tengono ancora il loro posto.
Il primo "albero filogenetico" della vita č probabilmente quello disegnato da
Ernst Haeckel
(1834-1919) nel 1866, che riproduco qui sotto per via della concretizzazione materiale
- un poco ingenua, se vogliamo - del concetto che noi (matematicamente) chiameremmo
"struttura arborescente orientata" in un albero vero e proprio: la rappresentazione
ad albero della filogenesi č infatti uno schema che ha avuto grande fortuna anche nella
linguistica (cfr. la discussione piů avanti nel paragrafo dedicato alle classificazioni storiche):
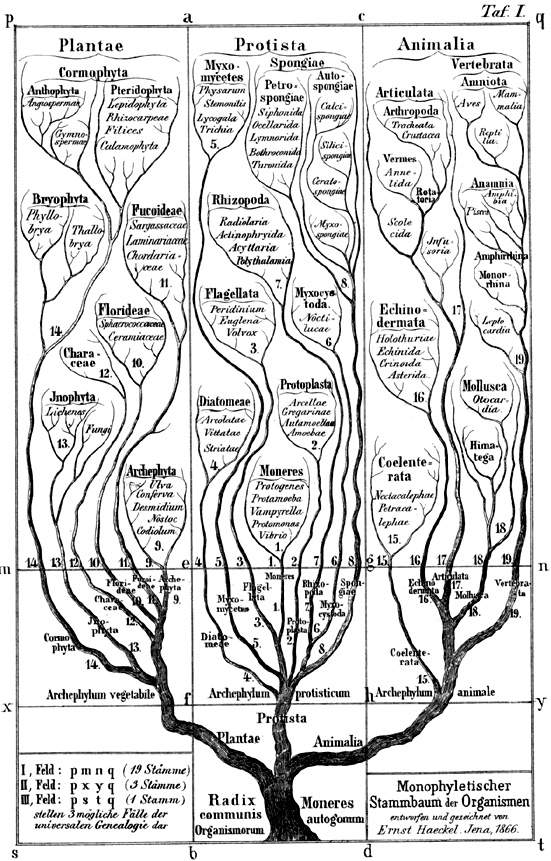
[tav. 6]
Il primo (1866) albero filogenetico della vita: il monophiletischer Stammbaum
di Ernst Haeckel, dalla sua Generelle Morphologie der Organismen: Allgemeine Grundzüge
der Organischen Formen-Wissenschaft, mechanisch begründet durch die von Charles Darwin
reformierte Descendenz-Theorie, Berlin, Georg Reimer, 1866. Potete utilmente confrontarlo
con il moderno albero della vita, che
avevamo presentato nelle lezioni precedenti, tanto dal punto di vista della struttura
(qui "Stammbaum" naturalistico, lŕ "struttura arborescente orientata" generata formalmente),
quanto da quello del contenuto (l'avanzamento delle conoscenze in poco piů di un secolo
di biologia č stupefacente!).
Il corrispondente della classificazione filogenetica delle specie
č, in linguistica, la classificazione storico-genealogica delle lingue, che ci occuperŕ
prevalentemente nei prossimi capitoli. Non č perň l'unico tipo di classificazione
praticato in linguistica.
Vi sono infatti vari altri sistemi, non storici, come (1) quello quantitativo (criterio base: numero di parlanti: scopo: programmi didattici,
interventi sociali, marketing, ecc.), (2) quello geografico (criterio: vicinanza areale; scopo:
identificare caratteristiche areali, diffusionali) o (3) quello tipologico (criterio: strutture
linguistiche, morfologiche o sintattiche; scopo: quantificare il numero di caratteristiche
grammaticali delle lingue del mondo, e comprenderne le relazioni). Sono in particolare
questi ultimi due ad avere maggiore interesse linguistico.
Intorno al secondo, il criterio geografico, in effetti,
si č sviluppata una particolare disciplina, la geografia linguistica, che ha trovato proprio
in Torino, specie intorno alle figure di Matteo Bartoli (1873-1946, istriano di
origine ma insegnante all'universitŕ di Torino dal 1908), prima, e dell'Istituto
dell'Atlante linguistico italiano, poi, uno dei suoi centri principali.
La classificazione il base al criterio tipologico, invece, praticata
largamente nel corso dell'Ottocento in base a criteri
morfologici, č risorta nella seconda metŕ del Novecento intorno ed a partire dall'opera
del giŕ menzionato linguista americano Joseph Greenberg (Some Universals of Grammar with
Particular Reference to the Order of Meaningful Elements, in Universals of languages,
edited by Joseph Greenberg, Cambridge (Mass.), MIT Press, 1966, pp. 73-113) concentrandosi
prevalentemente su criteri sintattici, e costituendosi in una sorta di corrente autonoma
della linguistica moderna.
2.0.4 La classificazione tipologica.
[Per il momento mi limito a rimandare al manuale di Graffi-Scalise.]
2.0.5 Filogenesi e tassonomia nelle classificazioni storiche.
Dopo le considerazioni che abbiamo fatto sulla natura delle lingue
e sul loro modo storico di costituirsi, č evidente come una tassonomia filogenetica
delle lingue sarŕ indubbiamente piů "difficile" da costruire e di solito meno netta
di quella biologica, da cui pure ha ereditato modelli di rappresentazione e logica.
Il modello di rappresentazione ad albero, normalmente noto col nome tedesco di
Stammbaum, che abbiamo visto adottato in biologia fin da Haeckel,
č stato subito (e, con vari ammodernamenti, resta tuttora) il sistema rappresentazionale
preferenziale. Si noti comunque come giŕ il primo e piů famoso degli Stammbaum linguistici,
quello disegnato da August Schleicher per l'indoeuropeo nel 1861 non solo fosse ancora piů
tempestivo di quello biologico di Haeckel del 1866 (l'Origine della specie
era uscita solo nel 1859!) ma era anche meno "ingenuamente" iconico
(niente tronchi, fronde e foglie ...) di quello di Haeckel, e pertanto, almeno
graficamente, piů simile alla nostra idea moderna di mero "grafo arborescente orientato"
(cfr. ad esempio quello, biologico e puramente cladistico,
della filogenesi degli eucarioti).
La maggiore "disinvoltura" nell'uso degli Stammbaumen contraddistingue comunque la pratica
dei linguisti (come anche quella dei filologi che disegnano gli "alberi" - chiamati
"stemmi" - della tradizione manoscritta od a stampa di un testo), confrontati spesso
con la necessitŕ di rappresentare situazioni non semplicemente lineari: si veda ad esempio
l'albero che disegnava una sessantina di anni dopo Schleicher il grande uralista
Lauri Kettunen
per le lingue uraliche, apparentemente ancora "ingenuo" e naturalistico alla Haeckel,
ma in realtŕ giŕ con soluzioni moderne quali la dislocazione dei rami, per le quali
va confrontato col mio piů "up-to-date"
albero "misto" del '95.
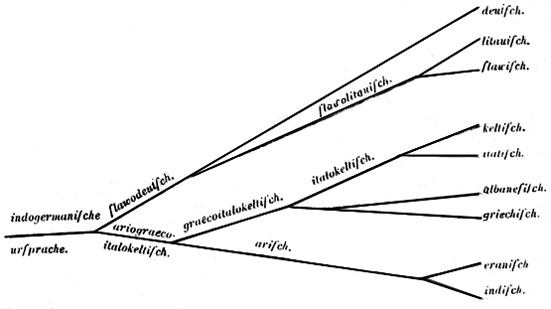
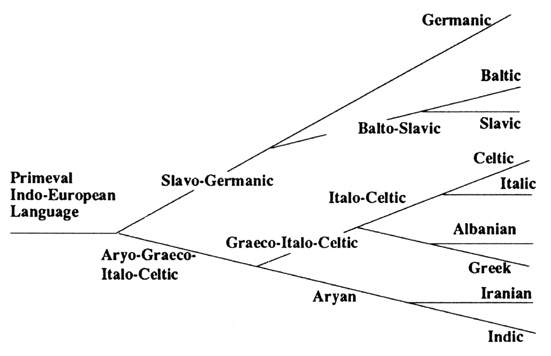
[tav. 7ab]
Stammbaumtheorie: il modello ad albero delle lingue indoeuropee secondo August
Schleicher, Compendium der vergleichenden Grammatik der indogermanischen Sprachen,
Weimar, Böhlau, 1861-1862 (2 vll.). Riprodotto (a) dalla versione originale (sesta
edizione, 1866, p. 9) ed in versione (b) "rammodernata" e volta in inglese da James
P. Mallory, In Search of the Indo-Europeans. Language, Archeology and Myth,
London, Thames and Hudson, 1989, p. 18.
Da confrontare con quello biologico di Haeckel e quello uralico di Kettunen per la struttura,
con quello moderno di Ivanov e Gamkrelidze anche per il contenuto.
La principale critica che si puň muovere alla "Stammbaumtheorie"
č quella di considerare la filiazione come un procedimento sostanzialmente unilaterale
per cui in linea di principio non si possono rappresentare incroci od influssi. Come
si č visto, perň, dai pochi esempi citati, si č riuscito a conseguire un minimo
di flessibilitŕ per rappresentare le influenze areali e le commistioni laterali
anche in questo sistema.
Un approccio rappresentazionale alternativo č invece quello del "modello ad onde"
(in tedesco Wellentheorie) proposto per l'indoeuropeo da Johannes Schmidt (1843-1901) nel 1872,
secondo il quale i mutamenti linguistici si propagano ad onde, seguendo ognuno una
propria isoglossa. Questo approccio č conseguente alla raggiunta consapevolezza che le lingue
sono sistemi fortemente composti, difficilmente semplificabili in un rapporto genetico
lineare; consapevolezza che č nata soprattutto in base agli studi sulla
costruzione delle lingue creole da parte del grande linguista Hugo Schuchardt (1842-1927) ed
alle esperienze della geografia linguistica di Jules Gilliéron (1854-1926) nata intorno
all'atlante linguistico francese. Una analoga reazione (ma ritardata, in quanto fuori dall'indoeuropeo)
č recentemente (2005) avvenuta per il sinotibetano, col modello delle cosiddette
fallen leaves
di George Van Driem, anche se con significative differenze (cfr. oltre al § 2.5.0).
[tav. 8]
Wellentheorie: il modello ad onde delle lingue indoeuropee secondo Johannes
Schmidt, Die Verwantschaftverhältnisse der indogermanischen Sprachen, Weimar,
Böhlau, 1872. Nel paragrafo 2.1 potrete confrontare una
versione moderna
del medesimo schema preparata da Raimo Anttila. Alcune delle "isoglosse" usate
sono le seguenti: (pongo tra parentesi il numero corrispondente nello schema di Anttila):
I. Indoiranico a vs. cetera e,a,o (=3); II. satem vs.centum
(=1); III. marche casuali in -m vs. -bh (=11); ecc. Provate ora ad
identificare le altre due isoglosse usando lo schema di Anttila come riferimento ...
Riprodotto da James P. Mallory, In Search of the Indo-Europeans.
Language, Archeology and Myth, London, Thames and Hudson, 1989, p. 19.
Se la valorizzazione della natura composita delle lingue č certo
ottima cosa, il modello della Wellentheorie non era altrettanto buono per finalitŕ
tassonomiche (ossia per produrre una classificazione genealogica delle lingue),
in quanto polverizza tutte le informazioni filogenetiche disponibili in una galassia
di micro-osservazioni puntuali, rendendo impossibile o perlomeno difficile cogliere
le grandi linee dei mutamenti. La tendenza odierna, in effetti (come ben riassume il manuale
di Graffi e Scalise a pp. 233-237), č quella di combinare in qualche modo le due tecniche,
disegnando Stammbaumen e tassonomie in qualche modo miste e multifattoriali, come
quelle che ho presentato per le lingue uraliche (cfr. lo Stammbaum
piů avanti) ed ancor piů per le baltofinniche (cfr. la tassonomia
piů avanti).
Non č infatti vero che la propagazione "orizzontale" delle onde
renda vana la individuazione (in base al metodo storico-comparativo) dei rapporti
"verticali" di genealogia descritti dagli schemi arborescenti: la realtŕ č che bisogna
saper discriminare gli strati diversi accumulati in una lingua e saperli ricondurre
alle tradizioni filogenetiche cui appartengono. La componente primaria (strato "genetico")
e le secondarie (strati "diffusi") vanno sceverate e trattate con lo stesso metodo.
Pensate al solito esempio dell'inglese: una analisi capillare di tutte le unitŕ della
lingua inglese che perň non sappia distinguerne le principali stratificazioni, potrebbe
anche concludere che si tratta di una lingua romanza abbastanza strana (sommando
elementi francesi anglonormanni e latini colti il lessico di origine latina in inglese
ha pari peso di quello di origine antico-inglese germanica; inoltre la maggior parte delle caratteristiche
morfologiche del germanico sono state perse): se invece distinguiamo tra strato antico-inglese,
strato latino, strato anglonormanno e strati piů recenti, ed applichiamo ad ogni strato
il metodo storico-comparativo otterremmo risultati affatto attendibili e che potremmo
rappresentare in un grafo ad albero (adattato ad hoc, certo, ma pur sempre dall'elevato
potere informativo: cfr. quello che ho disegnato per le lingue baltofinniche).
2.0.6 Appoggi extralinguistici all'evoluzione: archeologia, storia e genetica.
La complessitŕ delle operazioni interpretative che abbiamo visto
essere necessarie per la classificazione filogenetica rende se non necessaria certo
auspicabile anche la possibilitŕ di ricorrere ad aiuti extralinguistici. Per meglio capire il possibile uso di queste fonti, si
pensi all'esempio dell'inglese che avevamo fatto alla fine del paragrafo precedente:
sapere che dopo la battaglia di Hastings del 1066 la dinastia regnante in Inghilterra
non č piů anglosassone ma bensě normanna ci puň ben servire per individuare ed interpretare
lo strato linguistico francese anglonormanno; conoscere la storia dell'impero britannico
ci puň aiutare a risolvere l'origine di un certo gruppo di parole (come ad esempio
chutney, che č un adattamento del hindi cat,nî); sapere che una certa
area dell'Inghilterra č stata sotto il controllo danese (Danelaw) nell'alto
medioevo, ci puň dare il punto di partenza per distinguere uno strato germanico
(norreno) diverso da quello (anglosassone) della principale componente germanica
della lingua inglese moderna; ecc.
L'antichitŕ, dunque, delle attestazioni (che č stata una delle ragioni dello
stato per lungo tempo privilegiato della ricostruzione dell'
indoeuropeo)
e la ricchezza di informazioni storiche (cfr. la strategia che adotteremo per dare
conto delle famiglie turca, mongola e tungusa e dell' "altaico" in genere) sono da
questo punto di vista una fonte di conoscenza privilegiata che purtroppo č
disponibile solo per poche famiglie linguistiche.
Un caso particolare di aiuti extralinguistici č quello offerto dai
dati archeologici tradizionali: la loro importanza, soprattutto per la conoscenza
delle fasi antiche, non coperte dalla conoscenza storica, in cui proiettiamo le
protolingue capostipiti delle famiglie linguistiche che riscostruiamo, č intuitivamente
molto grande. Altrettanto grande deve essere perň la cautela nell'usarli per la
ricostruzione linguistica, in quanto le testimonianze dell'archeologia sono, in sé,
culturalmente e storicamente significanti ma linguisticamente mute. Pensate, per
comprendere il punto, al paradosso (l'esempio risale a Lyle Campbell) di un archeologo del
4.000 che faccia scavi in Brasile e trovi i resti di qualche Volkswagen: dovrebbe per
questo concluderne che in Brasile nel remoto secolo XX si parlava tedesco? Come vedete
la cautela č d'obbligo: l'importanza delle informazioni archeologiche č indubbia,
ma la loro interpretazione non č mai semplice.
Un esempio di ipotesi linguistica appoggiata sui dati dell'archeologia tradizionale
č la cosiddetta teoria dei Kurgan
sull'origine delle lingue indoeuropee (che tratteremo piů avanti).
Un altro tipo di dati archeologici (in molti casi anche di tipo piů moderno:
mappe dei pollini, datazioni al radiocarbonio, ecc.) spesso utili per la linguistica
storica sono quelli relativi all'insorgenza del neolitico. Mi permetto, en passant,
di ricordarvi la relativitŕ della cronologia archeologica, basata su una griglia
di caratteristiche solo culturali e non cronologiche assolute, per cui si puň avere
un "paleolitico" anche oggi, III millenio d.C., in alcune zone della Nuova Guinea,
mentre in Anatolia si era passati al "neolitico" giŕ nel VIII-VII millenio a.C.
L'evento "neolitico", in generale, č collegato alla diffusione dell'agricoltura, ed č
stato recentemente ancorato anche ad una cronologia assoluta grazie alle datazioni
al carbonio 14 (cfr. oltre).
L'insorgere del neolitico č importante perché puň forse essere collegato
all'apparizione delle famiglie linguistiche che ricostruiamo con maggiore profonditŕ:
l'esempio migliore č quello della teoria dell'origine neolitica
dell'indoeuropeo che
tratteremo nel prossimo capitolo.
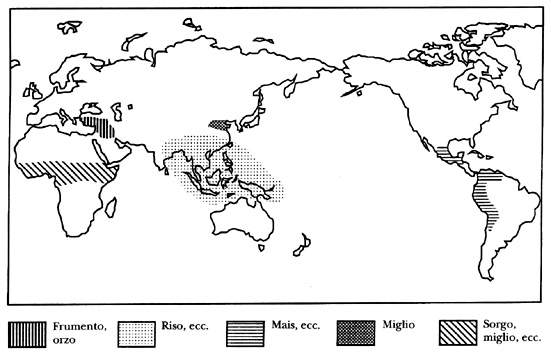
[tav. 9]
La nascita poligenetica del neolitico in piů centri indipendenti e legati alla domesticazione
di cereali selvatici diversi. Riprodotto da Luca Cavalli Sforza, Gčnes, peuples et langues,
Paris, Éditions Odile Jacob - Travaux du Collčge de France, 1996; trad. It. Geni, popoli e
lingue, Milano, Adelphi, 1996, p. 151.
Un altro aiuto esterno alla interpretazione storica dei dati linguistici
(con tutte le cautele del caso, naturalmente, per le quali valgono le stesse avvertenze
che per i dati archeologici) puň venire dai lavori della genetica di popolazione umana,
in particolare quelli sul campionamento di componenti geniche significative del DNA,
perseguiti negli ultimi venti anni da una scuola italiana (e nello specifico pavese)
di origine, ma di fatto accademicamente americana, centrata intorno alle figure di
Alberto Piazza e, soprattutto, di Luca Luigi Cavalli-Sforza.
Negli anni precedenti un grande lavoro era giŕ stato compiuto sulla sequenziazione
(e retrocostruzione filogenetica) del DNA mitocondriale (mtDNA). Su questo tipo di
procedura avevamo giŕ parlato nella precedente sezione a proposito della filogenesi
dei procarioti: il mitocondrio, infatti, per ricapitolare brevemente, č un organello
dotato di corredo genico proprio (distinto da quello presente nel nucleo, pertanto)
presente in (quasi) tutte le cellule eucariote, ed č, evoluzionisticamente, un
batterio (lo ritrovate infatti riportato nella tavola generale dell'albero della vita)
diventato simbionte della proto-cellula eucariota; il mtDNA č aploide e viene trasmesso
dalla sola linea materna; sequenziando un vasto campione (la cui scelta č stata comunque
discussa) di mtDNA della popolazione mondiale č stato perciň possibile ritracciare un
comune ascendente. Nonostante l'importanza di questi risultati, la scoperta č stata
in parte svuotata di valore dalla strumentalizzazione giornalistica, come se fosse
con ciň dimostrato che tutti discendiamo da un'unica donna (falso: il fatto che sopravviva la
linea evolutiva del DNA di una sola donna non significa che all'alba della specie uomo
ci fosse un'unica donna ... a parte il fatto che sarebbe stato molto triste per i protoominidi maschi,
e molto stanchevole per la nostra supposta protoominide femmina ;-), cui č stato
anche dato il nome di Eva (che strano...), ecc. ecc. Una descrizione scientificamente
corretta della questione č in Luigi Luca Cavalli-Sforza - Paolo Menozzi - Alberto Piazza,
Storia e geografia dei geni umani, Milano, Adelphi, 1997, pp. 156-166.
Per superare queste difficoltŕ Cavalli-Sforza si č invece concentrato sul DNA principale,
diploide, e piů facilmente portatore di mutazioni, ossia di errori nella replicazione. Le
mutazioni, in assoluto, sono rare (ricordate il discorso sulla stabilitŕ
del genoma che avevamo affrontato parlando dei procarioti?), dell'ordine di 1 su 200 milioni
di nucleotidi, ma in perlopiů avvengono in geni diversi, e lo stesso gene, nel tempo,
puň subire mutazioni diverse. In una popolazione possono pertanto esistere diverse varianti
(dette "alleli") di uno stesso gene, che verrŕ cosě detto "gene polimorfico". «I geni
polimorfici, o polimorfismi, costituiscono i marcatori usati in tutti i tipi di studi
genetici, inclusi quelli riguardanti l'evoluzione» (Cavalli-Sforza cit. p. 9). Il
metodo usato dal nostro studioso consiste, dato un elevato numero di geni
che presentino alleli diversi, nell'individuare delle "componenti principali" (CP), ossia
delle classi di polimorfismi che presentino tra loro una correlazione di percentuale
significativa. Per la popolazione mondiale sono state individuate sette CP, delle
quali le prime tre sono le piů quantitavamente rilevanti. Nella tavola seguente,
giusto per dare un'idea del tipo di metodo impiegato, riporto la composizione di
queste prime tre CP.

[tav. 10]
I geni polimorfici (marcatori genici) che presentano le correlazioni piů elevate e definiscono
le tre "componenti" geniche principali dell'umanitŕ; il segno "piů" o "meno" indica se
l'allelo č associato ad una correlazione negativa o positiva.
Riprodotto da Luigi Luca Cavalli-Sforza - Paolo Menozzi - Alberto Piazza, The
History and Geography of Human Genes, Princeton University Press, 1994; trad.
it. Storia e geografia dei geni umani, Milano, Adelphi, 1997, p. 252.
I dati esibiti in questa tavola non dicono certo molto ai
non biologi. Ma se si prova a tracciare su una mappa cromatica i risultati ottenuti
dallo studio di queste prime tre CP, otterremo un panorama che ci č molto piů informativo,
e che concorda con alcune delle conclusioni raggiunte dalla paleontologia (come l'origine
africana dell'Homo sapiens), dall'archeologia (alcune correlazioni con la diffusione
dell'agricultura neolitica) ed a volte, lo vedremo nei capitoli seguenti, eventualmente
anche dalla linguistica (ad es. si possono forse indivbiduare le componenti geniche dei baschi,
dei pre-lapponi
e (?) degli indoeuropei).
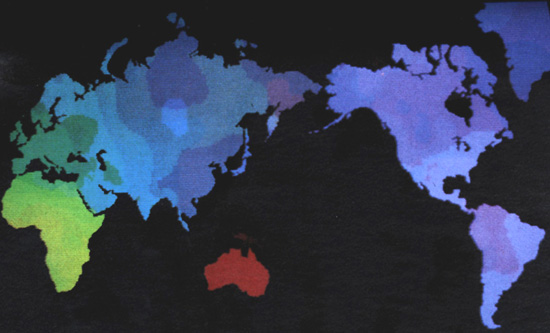
[tav. 11]
Mappa cromatica delle tre prime componenti geniche principali (DNA) della popolazione umana.
Il verde č associato alla prima componente, il blu alla seconda ed il rosso alla terza.
Ne risultano ben distinti gli africani (giallo-verde), i caucasiodi (blu-verde) e gli
australiani (rosso), mentre orientali ed amerindi mostrano la variazione genica maggiore
e condividono somiglianze da un lato con gli europei (violaceo-azzurrognolo nella Siberia
centrale) e dall'altro con gli australiani (violaceo in zone dell'America e della Siberia
antistante lo stratto di Bering). Chiaramente visibili sono anche i gradienti dovuti
alle mescolanze tra africani e caucasioidi nell'Africa settentrionale e tra caucasioidi
ed orientali nell'Asia centrale.
Riprodotto da Luigi Luca Cavalli-Sforza - Paolo Menozzi - Alberto Piazza, The
History and Geography of Human Genes, Princeton University Press, 1994; trad.
it. Storia e geografia dei geni umani, Milano, Adelphi, 1997.
I risultati di Cavalli-Sforza ( che, oltre tutto, ha esplicitamente
cercato di collegarsi anche alla linguistica), va perň avvertito che godono in genere di cattiva
stampa presso i linguisti, per via della sua malaugurata decisione di appoggiarsi
alle classificazioni linguistiche di Merrit Ruhlen, che ogni buon linguista sa essere, per
dirla il piů gentilmente possibile, perlomeno fantastiche. La diffidenza della comunitŕ
linguistica č certo giustificata, ma questo nulla toglie alla serietŕ scientifica
dei risultati biologici del lavoro di Cavalli-Sforza, i cui risultati biologici sarebbe
sciocco trascurare solo perché non si č d'accordo con le sue conclusioni linguistiche.
Anzi, č certo da apprezzare il tentativo di interdisciplinaritŕ e di ricerca di dialogo
con discipline diverse messo in atto da Cavalli-Sforza, e perciň č tanto piů da rammaricare
che abbia finito per trovare interlocutori sbagliati.
2.0.7 Linguistica storica e metodo storico-comparativo.
Il metodo storico comparativo, cui abbiamo piů volte riferito
nei paragrafi precedenti, e che trovate accuratamente descritto nel manuale di
Graffi - Scalise (ragione per cui non vale la pena di ripeterne la descrizione dettagliata qui)
prima nelle sue linee generali (p. 230-3), poi con l'esempio della ricostruzione
dell'indoeuropeo (237-240) ed infine in relazione alla natura delle "leggi fonetiche"
(pp. 241-7), č l'unico metodo scientifico per stabilire la parentela linguistica.
Qui ci limiteremo a fare da controcanto alla trattazione del Graffi - Scalise, evidenziando
e ponendo in rilievo alcuni nodi fondamentali.
Le sue origini, come anche per altre discipline "storiche", sono sostanzialmente
romantiche, e (nonostante la famiglia linguistica piů precocemente individuata sia
in realtŕ quella austronesiana: Frederick de Houltman
1603; e quella piů precocemente "dimostrata" scientificamente sia l'uralica: János
Sajnovics 1770), la costituzione
del metodo e tutte le sue vicende ottocentesche sono indissolubilmente legate
all'indoeuropeo (la cui individuazione, ma non ancora dimostrazione risale a
sir William Jones 1785)
e, secondariamente, alle due sottofamiglie germanica e romanza.
La sua data, storica, di nascita č, infatti, ufficialmente il 1816, quando cui il maguntintino Franz Bopp (1791-1867)
pubblicň il suo Über das Conjugationssystem der Sanskritsprache in Vergleichung
mit jenem der griechischen, lateinischen, persischen und germanischen Sprachen ('Sul
sistema di coniugazione del sanscrito in comparazione con quelli del greco, del
latino, del persiano e del germanico'), Frankfurt am Mein, 1816: la stessa data
in cui la nascente filologia testuale trovava il suo primo manifesto nel Properzio
di Karl Lachmann (1793-1851). Non erano mancati i precedenti: a risvegliare gli
interessi per gli studi orientali e del sanscrito era stato soprattutto Friedrich
Schlegel (1772-1829) col suo celebre Ueber die Sprache un Wiesenheit der Indier
('Sulla lingua e la sapienza degli indiani'), Heidelberg, 1908. Come vedete ci
troviamo davvero nel cuore del Romanticismo germanico.

[tav. 12]
1816: una sola data per due eventi strettamemnte collegati. Ecco i frontespizi
delle due opere che, antenati a parte, si possono considerare segnare la nascita
delle moderne linguistica storico-comparatica e critica testuale: (1)
Franz Bopp, Über das Conjugationssystem der Sanskritsprache in Vergleichung
mit jenem der griechischen, lateinischen, persischen und germanischen Sprachen,
herausgegeben und mit Vorerinnerungen begleitet von Dr. R. I. Windischmann,
Frankfurt am Mein, in der Andreĺnischen Buchhandlung, 1816; (2)
Sex. Aurelii Propertii Carmina emendavit ad codicum meliorum fidem et annotavit
Carolus Lachmannus, Lipsiae, apud Gerhard Fleischer Ju., 1816.
In effetti lo stesso tipo di logica filogenetico-ricostruttiva
caratterizza sostanzialmente tutte le classificazioni genealogiche, tra cui le piů
importanti hanno per oggetto le lingue (linguistica), i testi scritti (critica
testuale), o gli organismi biologici (biologia). Gli elementi usati cambiano ma
la logica combinatoria č la medesima: usare per la classificazione solo elementi
che possano disegnare classi esclusive.
Cosa voglio dire sarŕ forse piů chiaro se esaminiamo prima le procedure
che si usano in filologia (propriamente critica testuale) per la ricostruzione della
discendenza delle copie di un testo dal suo originale: non a caso avevo sottolineato
la coincidenza cronologica e culturale delle date di nascita del "metodo storico-comparativo"
in linguistica e "del metodo lachmanniano" in critica testuale. I "mutamenti"
che avvengono nel procedimento di copiatura di un testo sono in questo caso il
corrispettivo del cambiamento linguistico; la restituzione del testo originale č
il corrispettivo della ricostruzione della protolingua. Gli elementi che servono
per la ricostruzione sono in questo caso gli errori. Errori, perň, che devono
avere precisi requisiti logici che i filologi hanno avuto cura di esplicitare anche piů chiaramente dei
linguisti (che č la ragione per cui uso le loro conclusioni per meglio chiarire
le idee anche a noi linguisti; il riferimento č soprattutto all'aurea cinquantina
di paginette di Paul Maas, il grande filologo classico 1880-1964, uscito in prima edizione
tedesca nel 1927, in seconda nel 1950, ed in terza edizione, finalmente italiana, nel 1975:
Paul Maas, Critica del testo, traduzione di Nello Martinelli, introduzione
di Giorgio Pasquali, terza edizione, con lo "Sguardo retrospettivo 1956" e una nota
di Luciano Canfora, Fireze, Felice Le Monnier , 1975 "Bibliotechina del Saggiatore" 9).
Un errore per essere significativo deve essere allo
stesso tempo congiuntivo (non puň essersi generato indipendentemente in piů testimoni)
e separativo (non puň essere stato facilmente scoperto ed eliminato in qualche
testimone): una variante banale non riunisce necessariamente i testimoni che la
presentano, in quanto puň essere poligenetica, né li separa dagli altri che non la presentano,
in quanto possono averla eliminata per congettura; deve trattarsi invece
di un errore non banale, in modo da rendere improbabile tanto la poligenesi ( => congiunge
i testimoni che lo presentano in un'unica classe di discendenti del capostipite
dell'errore) e la correzione per congettura (=> separa i testimoni che non presentano
l'errore dalla classe di quelli che lo presentano).

[tav. 13]
L'applicazione della logica filogenetico-ricostruttiva alla critica testuale (il "metodo
lachmanniano") ossia alla ricostruzione della filogenesi di una tradizione manoscritta
(stemma codicum): la famosa "canzonetta" del Notaio Giacomo da Lentini (floruit
1230-1240), uno dei piů bei testi delle nostre origini. Č tramandata da tre manoscritti, P
(Palatino 418 poi Banco Rari 217) L (Laurenziano Rediano 9) e V (Vaticano latino 3793),
i cui rapporti genealogici furono chiaramente individuati nel 1952 da Gianfranco Contini
(Questioni attributive nell’ambito della lirica siciliana, in Atti del Congresso
internazionale di studi federiciani, Palermo, a cura del Comitato, 1952, pp. 367-395, poi in Gianfranco
Contini, Frammenti di filologia romanza. Scritti di ecdotica e linguistica (1932-1989),
a cura di Giancarlo Breschi, Firenze, Edizioni del Galluzzo - Fondazione Ezio Franceschini,
2007, vol. 1, pp. 205-234) grazie ad un importante manipolo di "errori significativi", cioč
tanto congiuntivi quanto separativi. Il caso č stato peraltro usato come paradigmatico
anche in un classico manuale di filologia italiana (Franca Brambilla Ageno, L'edizione
critica dei testi volgari, Padova, Antenore, 1975 "Medioevo e umanesimo" 22, pp. 135-145).
Testo secondo Poeti del Duecento, a cura di Gianfranco Contini, Milano - Napoli,
Riccardo Ricciardi Editore, 1960 "La letteratura italiana. Storia e testi" 2, tomo 1,
pp. 55-57; lezioni dei manoscritti in base a Giacomo da Lentini, Poesie, edizione
critica a cura di Roberto Antonelli, Roma, Bulzoni Editore, 1979, vol. I, pp. 23-37.
La nozione di "corrispondenza attraverso leggi fonetiche" del metodo storico -
comparativo in linguistica storica giuoca lo stesso ruolo della "distintivitŕ
dell'errore", intesa come intersezione di "separativitŕ" e "congiuntivitŕ", in critica testuale.
Il presupposto indispensabile č qui la nozione di legge fonetica che, elaborata
gradualmente nel corso della glottologia ottocentesca, raggiunse il suo acme presso
quella corrente di linguisti storici indoeuropei che si defině come neogrammatici
(propriamante in tedesco Junggrammatiker), attiva tra l'ultimo quarto dell'Ottocento
ed il primo decennio del Novecento. L'idea č che i mutamenti fonetici investono regolarmente
ed uniformemente tutto il lessico di una lingua, e non solo una parola qui ed
una lŕ, per puro capriccio. E, nonostante le innumerevoli discussioni che questo assunto
ha suscitato, oggi č sostanzialmente confermato, a patto che intendiamo la "regolaritŕ"
e la "assenza di eccezioni" su cui i neogrammatici tanto insistevano pressapoco come la
clausola ceteris paribus che va sottintesa ad ogni legge scientifica: la legge cioč
č regolare e senza eccezioni in assenza di altri fattori che interferiscano con detta legge.
A questo punto č abbastanza chiaro perché un fascio ordinato di corrispondenze
tra valori fonetici regolarmente diversi a valori semantici costanti sia l'elemento principe
che puň svolgere la funzione che in critica testuale svolge l'errore distintivo:
quello che si richiede per sostenere che due forme linguistiche (lingue figlie: LF1, LF2)
discendano da una ed una sola altra forma (lingua madre: LM) č qualcosa che accomuni
univocamente le figlie distinguendole da tutte le altre forme possibili (schematicamente:
[LM[LF1,2]] : Ln ...), cioč nella fattispecie forme lessicali (radici, temi)
o morfologiche (morfemi) individuate da costanza semantica ed accomunate da regolari
corrispondenze di suoni ("leggi fonetiche"). Una relazione che investa sistematicamente
entrambe le facce del segno (signifié=semantica e signifiant=fonetica) per
intieri fasci di forme, infatti, č improbabile si sia sviluppata per caso, poligeneticamente,
in piů lingue irrelate (č quindi congiuntiva) o possa essere stata completamente obliterata
in piů lingue relate (č quindi separativa).
E si badi che il requisito logico non č quello della "somiglianza
delle forme" (che anzi puň non esservi del tutto, od essere invece casuale), ma quello
della "regolare corrispondenza delle forme", elemento per elemento dell'espressione:
si richiede, in altre parole, un particolare tipo di relazione che non possa essere
fortuito, e non una somiglianza qualsiasi.

[tav. 14]
Un buon esempio di forme superficialmente affatto dissimili («dissimilar enough to
suggest they might be non-cognate» come dice François 2009 cit. qui sotto, p. 111),
ma che la presenza di corrispondenze regolari scoprono "cognate" č dato dalle forme per
'stare, sedere', te, lu ed o,
nelle tre lingue autoctone (tutte austronesiane, appartenenti ad un ramo dell'oceanico,
il Reef Islands, di recentissima
scoperta, cfr. § 2.6.7) che erano parlate (solo una, il teanu č oggi ancora vitale)
accanto al polinesiano tikopia (di piů recente introduzione) nell'isola di Vanikoro:
il teanu, il lovono ed il tanema. Vanikoro č un gruppo di due isole (abitate) maggiori,
Banie (la piů grande) e Teanu (la piů piccola), ed alcuni (disabitate) minori, circondate e riunite
da una cintura corallina esterna, appartenente all'arcipelago delle Reef Islands (Santa Cruz) nella provincia
di Temotu delle Isole Solomone; di 173 Km2 totali (10 piů di Modena), ha una popolazione
di c. 600 melanesiani parlanti teanu e c. 200 polinesiani parlanti tikopia (cioč
una popolazione complessiva di poco inferiore a quella che Modena avrebbe per kilometro quadro, nel 2010
secondo l'ISTAT 999!).
Nella tavola (che attingo da Alexandre François, The Languages of Vanikoro: Three
Lexicons and One Grammar, in Discovering History
Through Language: Papers in Honour of Malcom D. Ross, edited by Bethwyn Evans, Canberra,
Pacific Linguistics: Research School of Pacific and Asian Studies - The Australian
National University, 2009 "Pacific Linguistics" 605, pp. 133-126, p. 111) impagino
alcune corrispondenze per la *t protooceanica, che evidenzio in rosso. Le tre
lingue, peraltro, al di lŕ della diversa fonetica, hanno una struttura grammaticale chiaramente identica.
Anche la ricostruzione filogenetica in biologia, soprattutto quando
poteva ricorrere solo alle caratteristiche morfologiche (con la genetica molecolare
il ricorso a procedure statistiche diventa inevitabile), obbediva allo stesso schema.
La "cladistica", come oggi si chiama la metodologia allestita da Willi Hennig (16913-1976)
durante la guerra e pubblicata nel Cinquanta (Grundzüge einer Theorie der phylogenetischen Systematik,
Berlin, Deutscher Zentralverlag, 1950; la diffusione perň risale solo alla
traduzione inglese: Willi Hennig, Philogenetic Systematics, translated by D. D. Davis
and R. Zangerl, Chicago, University of Illinois Press, 1966; il nome di cladistica
per quello che Hennig chiamava tradizionalmente sistematica filogenetica č dovuto
a Ernst Mayr) distingueva infatti tra "plesiomorfie" (caratteri ancestrali e primitivi) ed "apomorfie"
(caratteri derivati o specializzati): solo i caratteri plesiomorfi sono "distintivi"
nel senso di cui sopra, dato che gli apomorfi possono essere poligenetici. Anche la
cladistica moderna, prevalentemente molecolare, ha cambiato tecniche e strumenti
ma non ha modificato la logica di fondo (cfr. Peter L. Forey - Christopher J. Humphries
- Jan J. Kitching - Robert W. Scotland - Darrell J. Siebert - David M. Williams, Cladistics.
A Practical Course in Systematics, Oxford, Clarendon Press, 1992 "Systematics
Association Pubblications" 10).
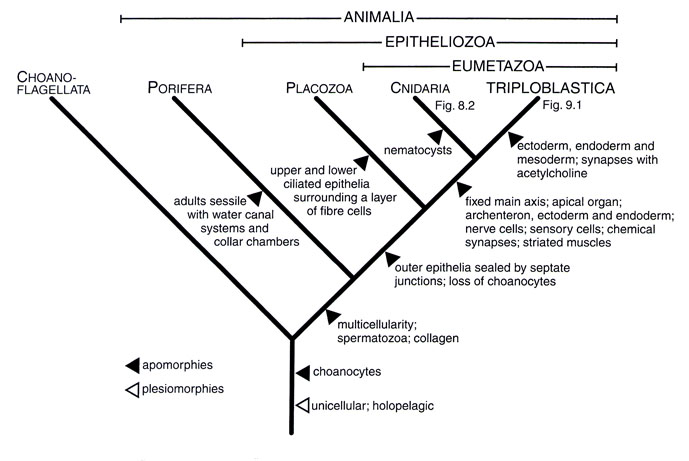
[tav. 15]
Apomorfie e plesiomorfie nella biologia evoluzionistica tradizionale, morfologica
(quella moderna, basata sui genomi, ha tecniche molto piů complesse, in genere note
col nome di cladistica, le cui basi logiche sono perň, ancora una volta, le medesime):
come esempio ho scelto la radice della gerarchia arborescente degli animali,
o piů accuratamente Metazoa, che avevamo giŕ visto nelle sue linee generali
addietro, nel quarto capitolo
della prima parte. Riprodotto da Claus Nielsen, Animal Evolution. Interrelationships
of the Living Phyla, 2nd edition, New York, Oxford University Press, 2001, p. 18.
Si noti nell'esempio che la comparsa dei coanociti (particolari cellule flagellate a collare)
č una sinapomorfia di coanoflagellati
ed animali; la multicellularitŕ, poi, all'interno della gerarchia nella posizione indicata
č una sinapomorfia degli animali che li distingue dai coanoflagellati, ma considerata
dall'esterno č una plesiomorfia (si č sviluppata indipendetemente, ad esempio,
nei vegetali ed in alcuni phyla di funghi): la definizione di una caratteristica
come (sin)apomorfica o plesiomorfica č sempre relativa.
Lasciando l'illustrazione dei dettagli del funzionamento concreto del
metodo storico-comparativo al manuale, qui vorrei solo far comprendere meglio oltre alla sua
logica generale, il peculiare status ontologico e scientifico dei suoi risultati:
molti dei fraintendimenti sulla possibilitŕ di altri sistemi di comparazione, e sulla
portata scientifica dei risultati del metodo storico-comparativo, derivano infatti
proprio da una imperfetta comprensione della logica in base alla quale esso funziona.
Tutte le lingue, come spesso abbiamo detto, sono delle entitŕ complesse, frutto della
stratificazione storica di piů componenti diffusionali su una genealogica; il metodo
storico-comparativo non vi permette di dire quale fascio di corrispondenze sia
di origine diffusionale e quale genealogico, vi dice solo che tali strati esistono
e sono da attribuire ad una realtŕ storica, quale essa sia va perň deciso (quando possibile)
in base ad altre ragioni. Un esempio "facile" puň esseree la lingua inglese, che ha
due strati principali, uno franco-latino (statisticamente maggiore) ed uno germanico
(statisticamente di poco inferiore), che il metodo storico-comparativo confrontando
l'inglese, ad esempio, col francese e con il tedesco, permetterebbe di distinguere
nettamente, individuando correttamente i due fasci di corrispondenze, ma non
potrebbe dirci quale dei due sia quello genealogico. Scoprirlo, per l'inglese, č
perň facile, potendocelo dire la storia. In moltissimi altri casi in cui non siamo
cosě fortunati ciň non č possibile, e si č fatto spesso dire al metodo quello che non puň,
o lo si č accusato di insufficienza, passando dall'indebito al gratuito: un esempio
principe č il problema dell'altaico (cfr.).
Varie teorie, infine, sono state proposte sulla natura delle forme
che il metodo storico - comparativo ricostruisce: si va da posizioni assolutamente
"realiste" a posizioni piů astrattamente "formaliste". Per le prime la ricostruzione
produce uno stato di lingua "reale" come qualsiasi lingua effettivamente usata da
una comunitŕ linguistica in un dato punto del tempo e dello spazio. Per le seconde,
invece, le forme ricostruite sono di natura essenzialmente algebrica e formale:
la protoforma č, in sostanza, solo la migliore funzione che genera i dati delle lingue
reali. Questa impostazione "funzionale" (nel senso matematico) della ricostruzione,
fu illustrata magistralmente dal solito Hjelmslev, di cui abbiamo giŕ molto parlato
(cfr. Louis Hjelmslev, Sproget. En introduktion, Charlottenlund, The Nature
Method Center, 1963; trad it. Il linguaggio a cura di Giulio C. Lepschy, Torino,
Einaudi, 1970 "PBE"; il libro, a differenza di altri scritti di Hjelmslev, č di
facilissima e gradevole lettura: un classico da consigliare ad occhi chiusi ...).
Come si sarŕ ormai compreso č solo questa interpretazione funzionalistica delle
ricostruzioni che davvero concorda con tutte le altre osservazioni che abbiamo condotto
finora: se le lingue da sottoporre alla comparazione vanno trattate come diasistemi
ed analizzate nelle loro componenti, la protolingua che da queste sommatorie deriva
non sarŕ altro che la matrice che meglio descrive tali diasistemi. Tutte le istanze
piů propriamente realistiche, come la plausibilitŕ fonologica, la coerenza tipologica,
e, a partire da queste, la ricostruzione interna, sono tutte operazioni successive
alla imprescindibile ricostruzione algebrica, ed operazioni da effettuare sempre
con tutta la cautela che la specificitŕ imposta dall'oggetto in questione (che NON
č una lingua "vera" a tutti gli effetti, come solo gli ingenui possono pensare,
ma bensě solo la nostra migliore approssimazione descrittiva
al problema delle origini delle lingue "vere"). Ed a questo scopo anche altri dati
esterni, quali la genetica, l'archeologia, e la storia possono, come abbiamo visto,
pure contribuire.
2.0.8 Altri metodi?
L'unica, presunta, alternativa al metodo storico - comparativo
che sia stata proposta dal dal 1816 ad oggi č il metodo della mass comparison
proposto da Joseph Greenberg (che ormai ben conosciamo per il suo contributo alla
tipologia linguistica) ed adottato tra gli altri da Merrit Ruhlen (che pure conosciamo
fin troppo bene per le sue tesi truffaldine sulla monogenesi delle lingue).
Non č qui la sede per una disamina dettagliata: per una critica sintetica potete,
ad esempio, riferirvi ad alcune pagine del piů volte citato Lyle Campbell (American
Indian Languages. The Historical Linguistics of Native America, New York - Oxford,
Oxford University Press, 1997, pp. 209-214). Qui basti dire che, teoricamente, ci
aspetteremmo che la teoria della "mass comparison" non possa funzionare, dato che viola la "logica" della ricostruzione
che abbiamo faticosamente individuato nel paragrafo precedente.
Di fatto, per essere
obiettivi, la teoria di Greenberg ha dato risultati che vanno dai sostanzialmente corretti agli assolutamente
sbagliati: la classificazione delle lingue dell'Africa che fu la prima grande impresa
di Greenberg (Languages of Africa, Bloomington, Indiana University Press, 1963)
č stata, almeno nelle sue grandi linee, confermata dalle ricostruzioni
finora conseguite con il metodo tradizionale (che richiede lavori molto piů lunghi
e complessi del metodo di Greenberg); l'analogo lavoro compiuto da Greenberg per le
lingue native delle Americhe (Language in the Americas, Stanford, Stanford
University Press, 1987) ha invece dato risultati ritenuti unanimamente inaccettabili
da tutti gli amerindiologi, e che sono spesso stati smentiti dalle ricostruzioni
"tradizionali". L'unica conclusione possibile č che a volte anche le teorie sbagliate
per caso ci imbroccano, specie se usate (o dimenticate?) da studiosi che conoscono
peraltro molto bene il loro campo (come fu il caso di Greenberg e le lingue africane),
ma non per questo cessano di essere sbagliate ...
Anche una "tecnica ausiliaria" che ha aumentato molte speranze, la lessicostatistisca,
si č presto rivelata infondata, essendo basata sul presupposto (errato) che il lessico
cambi con un ritmo costante o perlomeno misurabile e prevedibile: per renderrsi conto
della assurditŕ dell'assunto basta pensare a come un islandese moderno riesca a
leggere con discreta sicurezza un testo classico di un millennio fa, mentre un
inglese moderno non riesce a fare altrettantio con un testo in antico inglese,
né un francese con un testo antico francese.
Se "metodi" per la comparazione migliori del tradizionale (che in mano
a studiosi competenti e scrupolosi sta continuando a dare ottimi frutti anche nelle aree orientali
ed oceaniche ancora da dissodare, come provano ad esempio i lavori di Robert Blust
e Malcom Ross in Austronesia e Papua) non ne sono stati di recente "scoperti", pure
si sta ultimamente assistendo, al di lŕ del troncone originario dei monogenisti alla Greenberg,
ad una vera esplosione di lumpers che comparano (perlopiů a muzzo) qualsiasi
cosa con qualsiasi cosa, deridendo come splitters tutti i comparativisti sani
che (cosa per loro incredibile) esigono che le asserzioni per essere scientifiche
(anziché fantastiche) vadano sempre dimostrate con prove, e prove buone. Da tutti questi ciarlatani,
spesso sposati come santi dai media creduloni e sensazionalisti, non ci si stanchi
mai di guardarsi. Valgano cosě, per concludere queste riflessioni metodologiche,
le recenti considerazioni di Matisoff, il grande sinotibetanista, in un paragrafo
che significativamente intitola Perils and caveats, che riporto qui sotto.
There is a constant temptation among linguists to be the firsts
to 'discover' a new subgroup within a recognised family (cf. Thurgood 1984; van
Driem 1997), or a farflung relationship between language families on opposite sides
of the globe.
The easiest proposals to dismiss as chimerical are those which depend entirely on
surface similarity among forms from modern languages, without bothering to attempt
reconstructions of proto-forms in the languages to be compared. In this category
belongs Greenberg 1987, an attempt to group all the languages of the Western
Hemisphere into three families: 'Amerind', Eskimo-Aleut and Na-Dene. As an exercise
in megalocomparison, I had no difficulty in coming up with about 50 good-looking
'cognates' between Amerind and Proto-Sino-Tibetan or Proto-Tibeto-Burman. This
exercise took about three hours by the clock, but did not fill me with any exhilaration,
only a vague depression that this sort of thimgs was so easy.
Even more dangerous are serious megalocomparative efforts that are clothed in the
trappings of the traditional comparative method, that use reconstructed forms, and
that puport to show 'regular correspondences' among 'cognates'. Despite the occasional
brilliance of such endeavours, what they all have in common is tortured
sound-correspondences, disregard of counter-examples to 'sound laws', and unconstrained
semantic latitude.
We all have to take a deep breath, and admit that the comparative method has intrinsic,
ineluctable limitations. The remote linguistic past is a dark tunnel, and the torch
of the comparative method can only illuminate it so far. It goes without saying that
lexicostatistics - which is at best a feeble adjunct of the comparative method -
cannot cannot push the light back any farther.
[tav. 16]
James A. Matisoff, On the Uselessness of Glottochronology for the Subgrouping
of Tibeto-Burman, in Time Depth in Historical Linguistics, edited by
Colin Renfrew, April McMahon and Larry Trask, Cambridge (EN), The McDonald Institute
for Archaeological Research, 2000 "Papers in the Pehistory of Languages", vol. 2 pp.
333-371, p. 357.